Motivation
CV 和 NLP 领域的一些工作发现对各层做 aggregation 能够获得比较好的效果,因此尝试将该思想加入 NMT 中,通过 聚合各层信息 来提升翻译质量。尽管残差已经是利用了多层信息,但这种简单的单步融合的方式太“浅”。
- Author: Zi-Yi Dou, Zhaopeng Tu
Methods
采用的聚合方法有 layer aggregation 和 multi-layer attention
Layer aggregation
Layer aggregation 选用了四种策略:
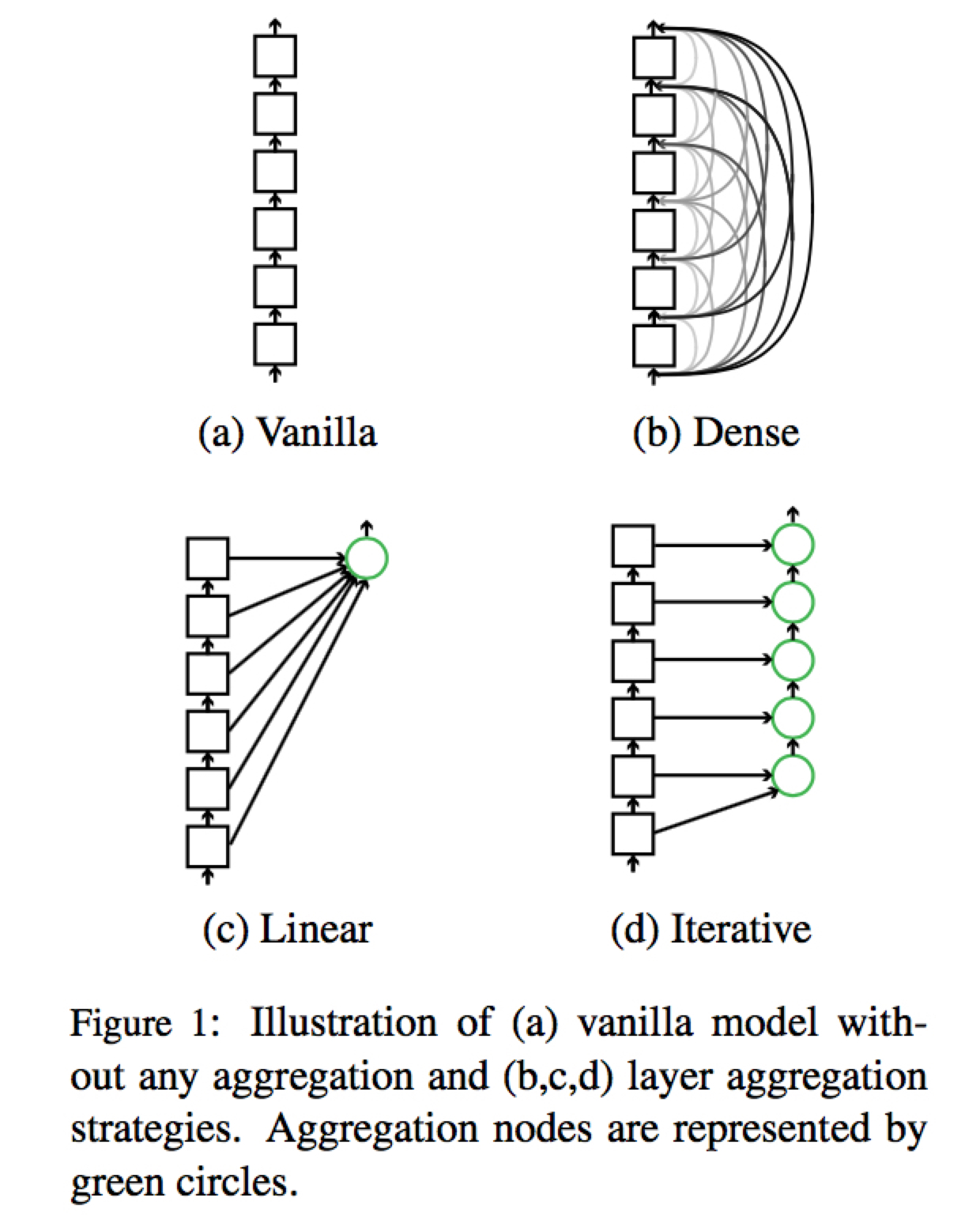
Dense Connection
Linear Combination
这个在作者后来的文章 AAAI18 的 Dynamic Layer Aggregation 中作为 baseline (static aggregation)
Iterative Aggregation
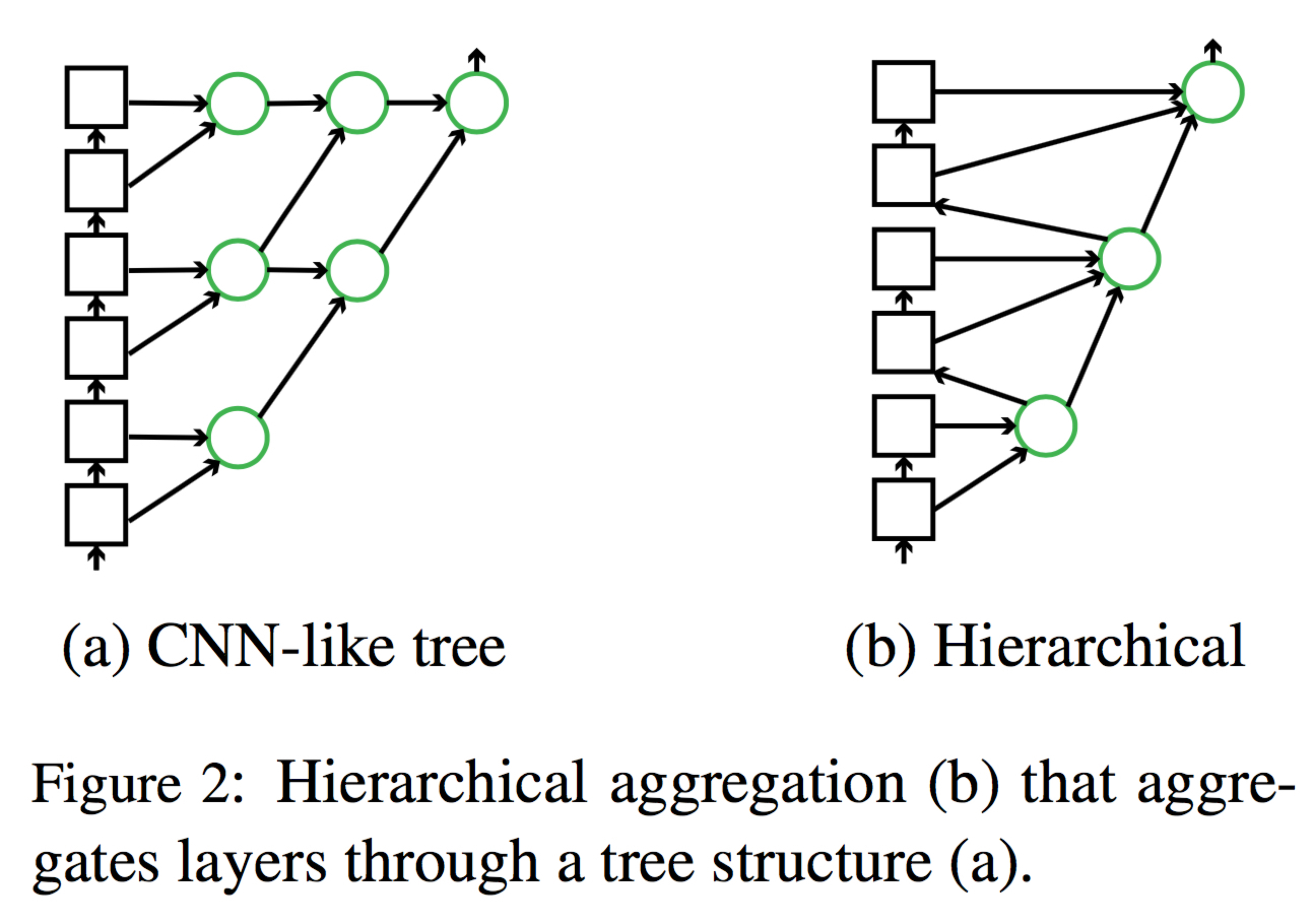
Hierarchical Aggregation
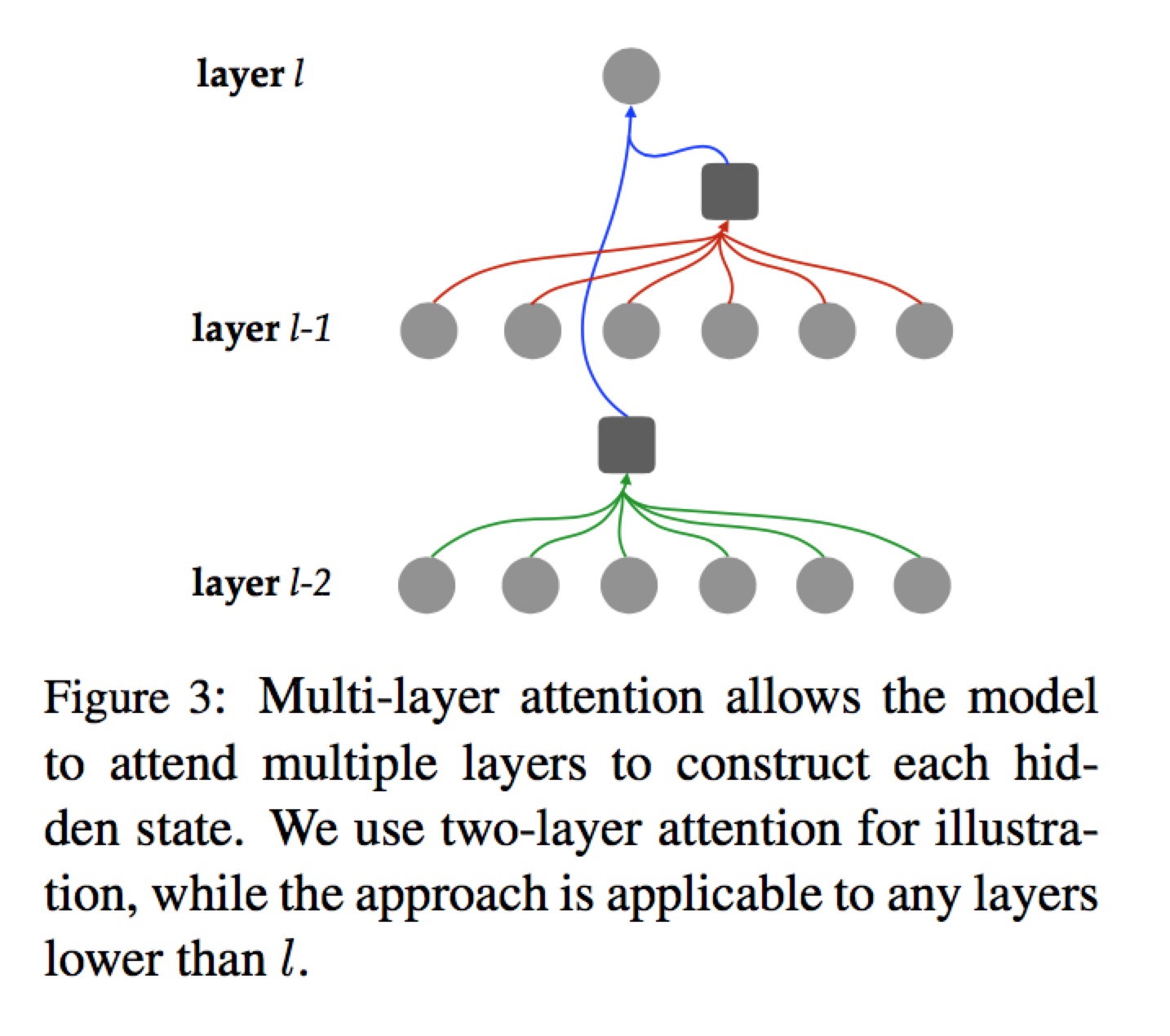
Multi-Layer Attention
只在 encoder 和 decoder 内部进行,不改变原来的 encoder-decoder attention
简单来说就是考虑之前所有层的输出
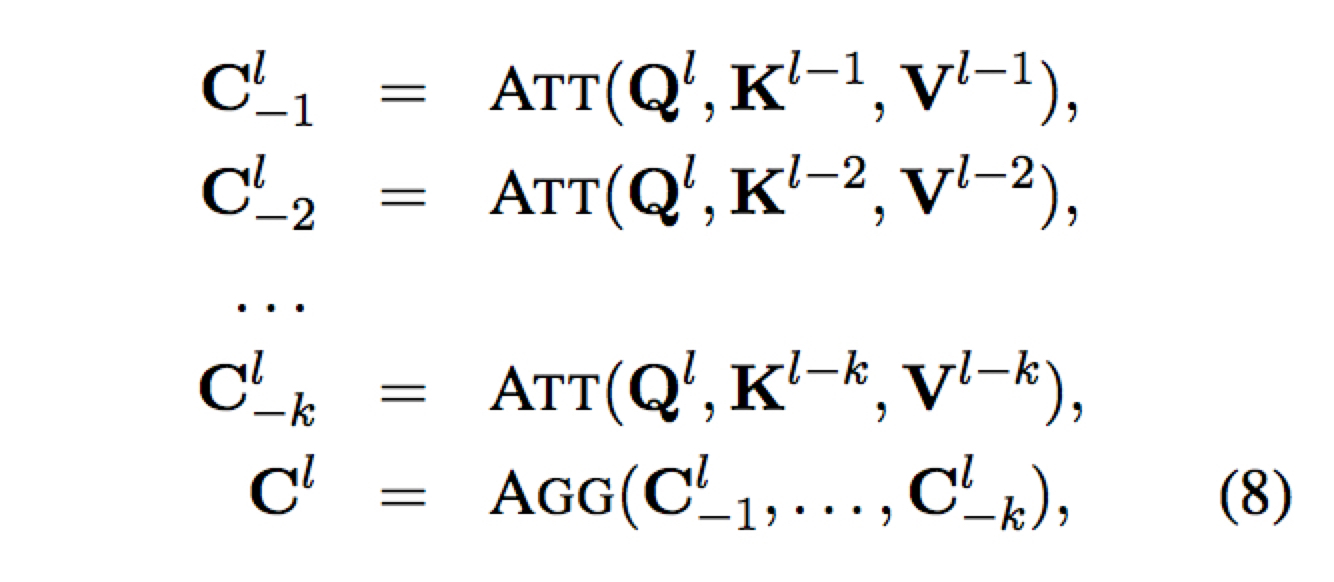
Layer Diversity
为了保证各层学到的特征存在差异,增加一项 regularization
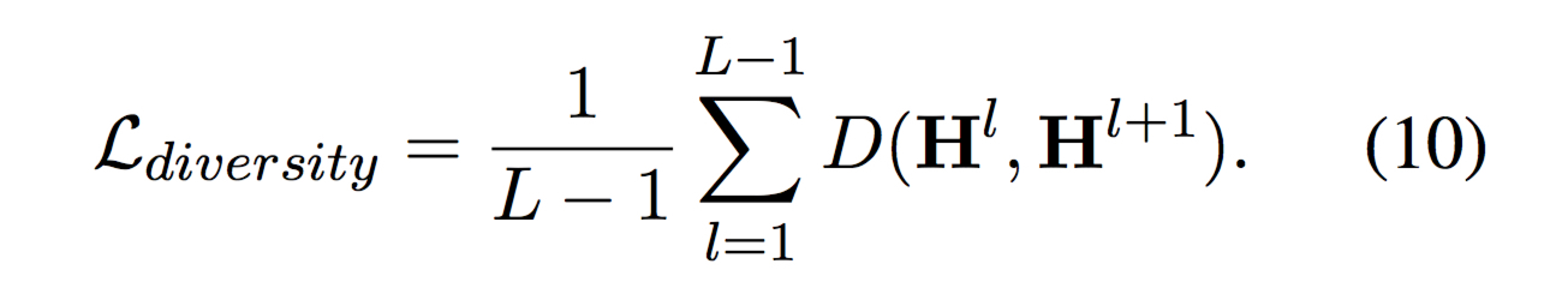
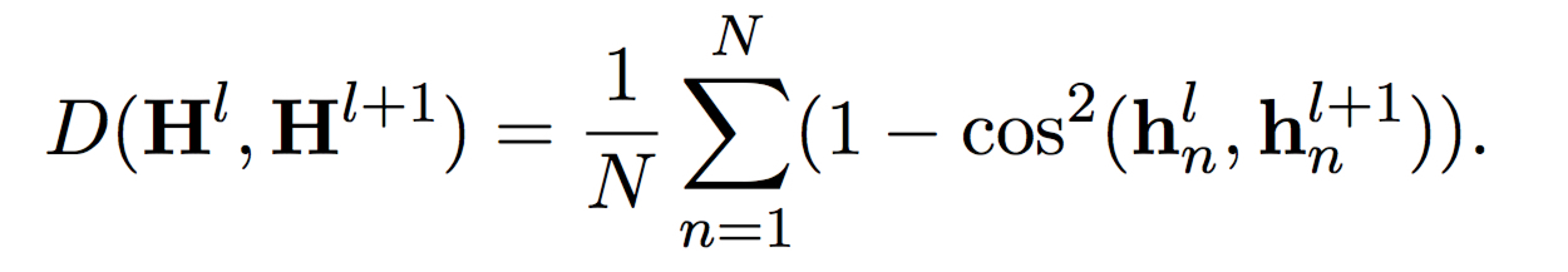
Experiments
BLEU
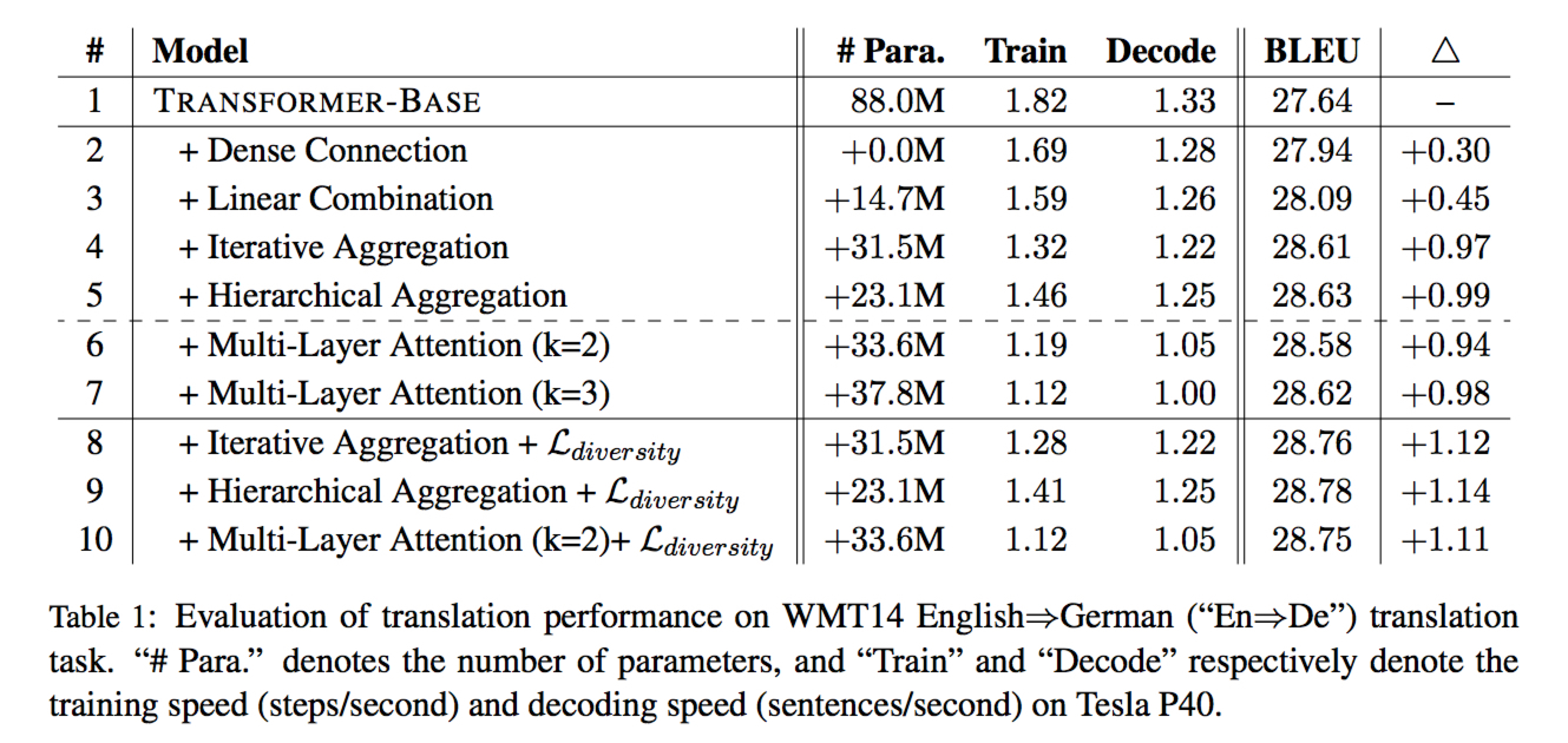
四种 Aggregation 中,前两种相对 “shallow”,实验中效果没有后两种好,但也有提升
最好的方法是 Hierarchical + Regularization
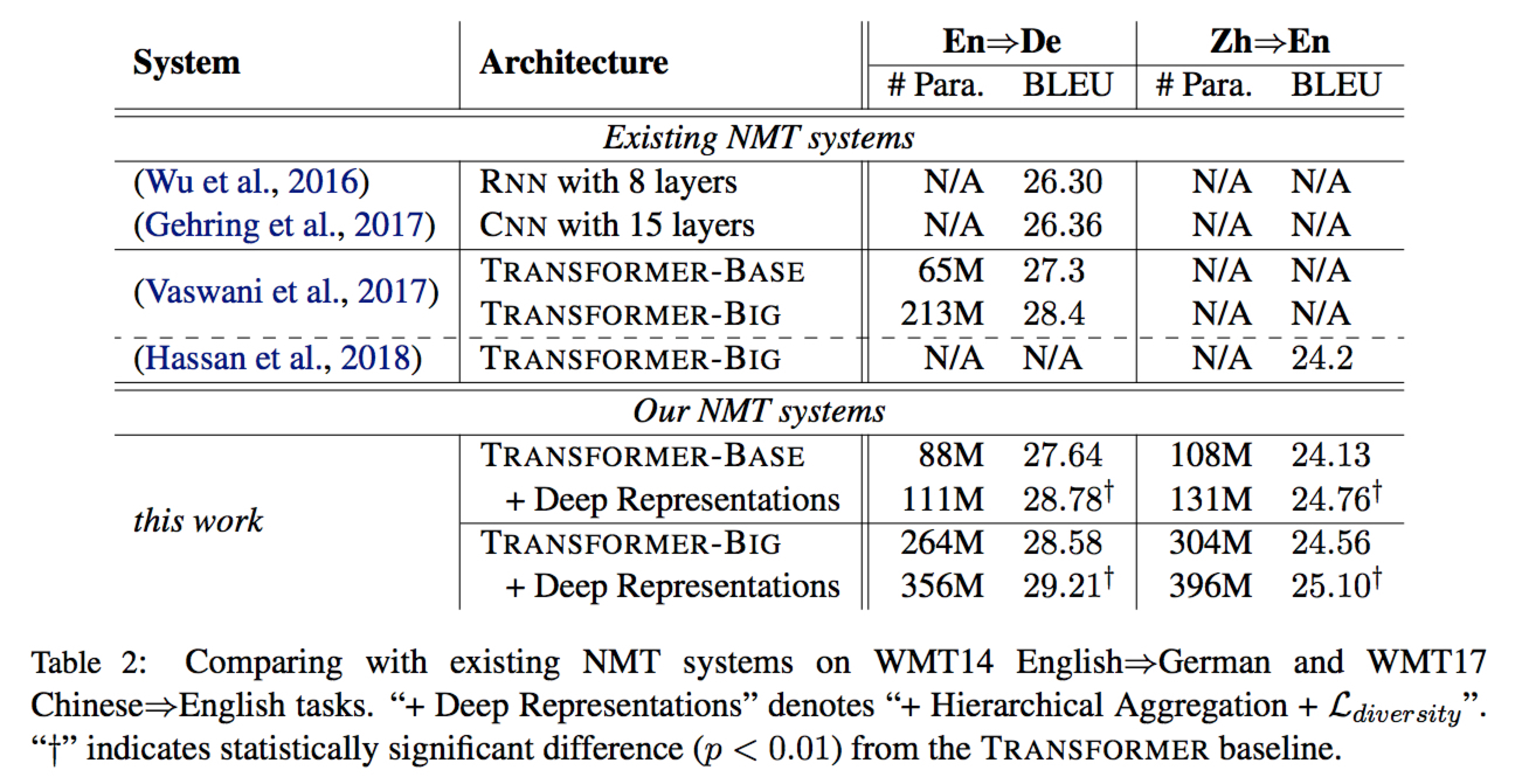
- Base + Deep Representations 比 Big 模型效果要好
Visualization of Aggregation

作者对层次聚合(Hierarchical)效果做了可视化,x轴的 $\widehat{H}^{1}$ 等是聚合后的结果, y轴是每次层次聚合利用的三个输入层,权重大致表示聚合时的各层信息权重。作者提出两点观察:
- 聚合方法倾向于低层信息(权重较大),这能说明该方法的必要性。
- 文中提出的 Regularization 方法确实能够使得聚合层更均匀的利用所有输入(b与a对比)
Questions
ELMo 也是类似的多层聚合的方式,他们的解释是 stacked Bi-LSTM 不同层学到的特征有所区别,比如底层学到的是句法信息,高层学到的是语义信息,并在一定程度上做了实验验证这一点。本文的实验结果是否说明 Transformer 也有这种类似的现象?如果有,是不是意味着这在某种程度上契合人理解语言的过程;如果没有,那这种多层聚合的效果提升又来源于哪里。
在实验部分提到了聚合可视化,为什么在加 Regularization 前(可以理解为更接近目前的 NMT 训练效果)聚合方法会倾向于低层信息,我觉得这里面可能是有一些玄机的。
关于 Layer Aggregation 本身我有一些疑问,尤其是对于 Transformer 来说,encoder 和 decoder 内部的序列长度都是动态的,比如 encoder 的每一层输出就是
[batch_size, input_length, hidden_size],那么对应的聚合参数的 shape 在每个 batch 的运算中也会不一样。目前的想法是对序列按 max_len 做了 padding 。